Agent Blackbox
The Challenge
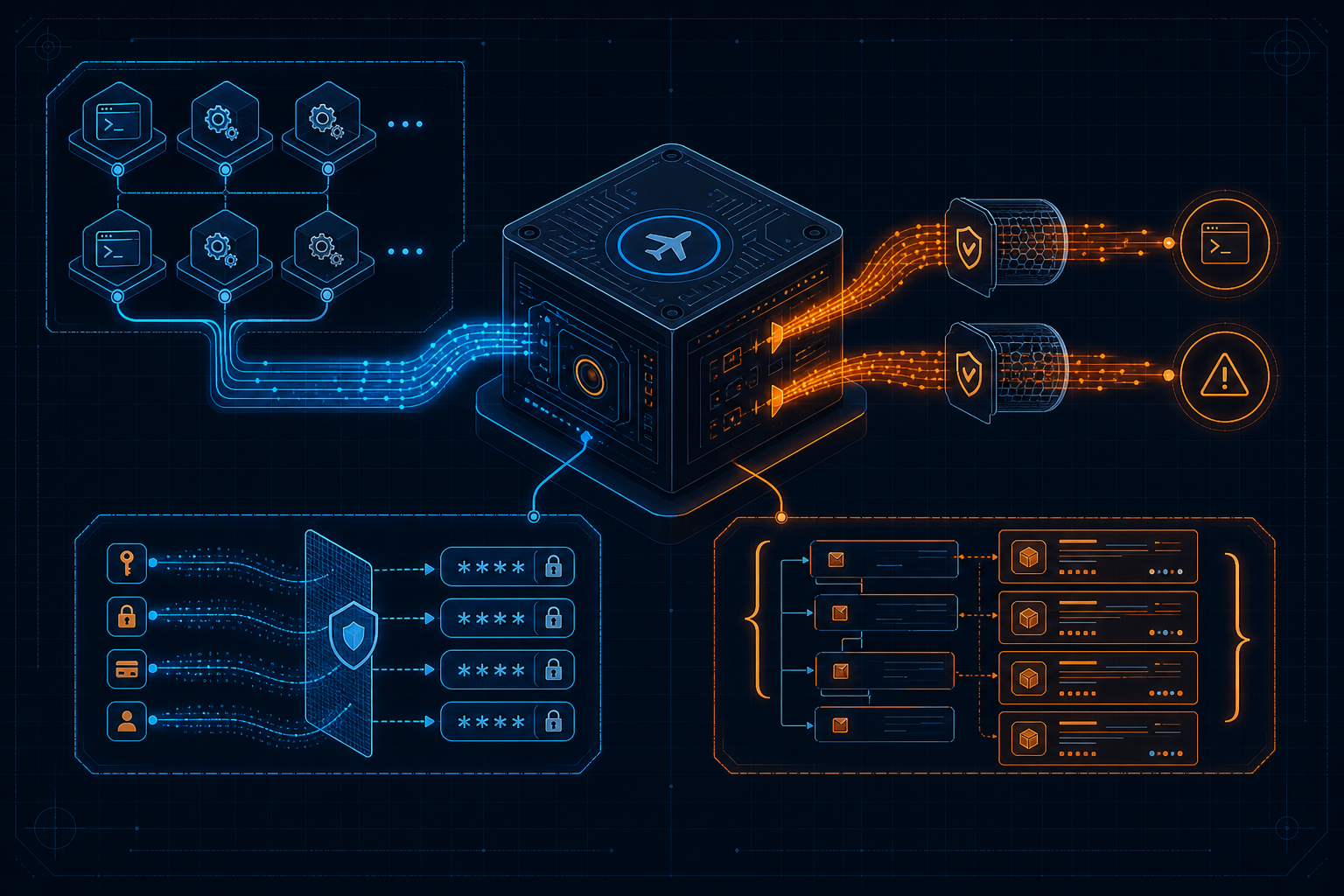
AI agents can edit files, call tools, run tests, hang in subprocesses, hallucinate success, or fail through flaky network/model dependencies. Traditional QA automation catches deterministic UI/API regressions, but agent runs need evidence capture across prompts, commands, files, logs, timing, and side effects.
The Solution
Built a Python CLI that records agent and automation runs locally, streams output live, redacts sensitive data, classifies failures, exports Markdown/HTML postmortems, and turns ambiguous agent behavior into inspectable evidence. The product direction extends proven automation testing practices into AI-agent reliability testing.
Agent Reliability Flight Recorder
Agent Blackbox translates mature automation testing discipline into local-first evidence capture for AI-agent runs.
- ✓Active subprocess stream recording
- ✓Sanitized raw/safe output separation
- ✓Run-level diagnosis and failure classification
- ✓Markdown and visual HTML postmortem export
- ✓Gateway, cron, Claude Code, and Codex-oriented diagnostics
- ✓Local-first privacy posture with no cloud upload
- ✓Agent testing roadmap: replay, mutation, eval harnesses, and policy checks
Agent Blackbox: Applying Automation Testing Discipline to AI-Agent Reliability
Agent Blackbox is a local-first flight recorder for AI coding agents. The idea is simple: if an agent can edit files, run commands, call tools, and claim success, then teams need a reliable way to inspect what actually happened.
My automation testing background is the foundation here. Years of stabilizing brittle browser flows, debugging CI failures, designing test frameworks, and turning vague failures into reproducible evidence map directly onto agent reliability.
The Problem
AI-agent runs fail differently from normal scripts.
A coding agent can:
- edit the wrong file
- skip the verification command
- hallucinate that tests passed
- hang inside a subprocess
- leak sensitive output into logs
- over-edit unrelated files
- fail because of model, network, or tool instability
Traditional logs show fragments. They rarely explain the incident.
The Testing Insight
Serious automation testing already solved a version of this problem.
Good automation systems need:
- repeatable execution
- strong assertions
- useful failure artifacts
- environment and timing visibility
- safe redaction
- traceable root cause
- reports that humans can act on
Agent reliability needs the same discipline, just applied to prompts, tools, terminal commands, files, and model-driven decisions.
The Solution
Agent Blackbox records and diagnoses agent runs locally.
It captures command metadata, stdout, stderr, timing, exit codes, raw output, sanitized output, and failure markers. Then it turns that run into a postmortem instead of leaving the developer to manually scrape terminal history.
Current capabilities include:
- active subprocess stream recording
- sanitized output separation
- run-level failure classification
- Markdown postmortem export
- visual HTML report export
- Hermes gateway and cron diagnostics
- Claude Code and Codex-oriented session analysis
Why Local-First Matters
Agent traces may contain prompts, source code, credentials, customer data, stack traces, and internal file paths.
A reliability tool that uploads everything by default creates a new security problem. Agent Blackbox is local-first by design: inspect the run on the machine where it happened, redact what must not leave, and only share sanitized artifacts.
Reliability Roadmap
The next layer is agent testing, not just agent observability.
Planned project directions:
- deterministic agent failure fixtures
- agent behavior mutation testing
- risky-action policy checks
- replayable timelines
- expected-diagnosis snapshots
- eval harnesses for real automation engineering tasks
The metric I care about is not dashboard prettiness. It is whether the system catches agent failure modes before humans trust the next run.
Outcome
Agent Blackbox turns opaque agent behavior into evidence.
That is the bridge from traditional automation testing to AI-agent reliability: same discipline, new execution surface.