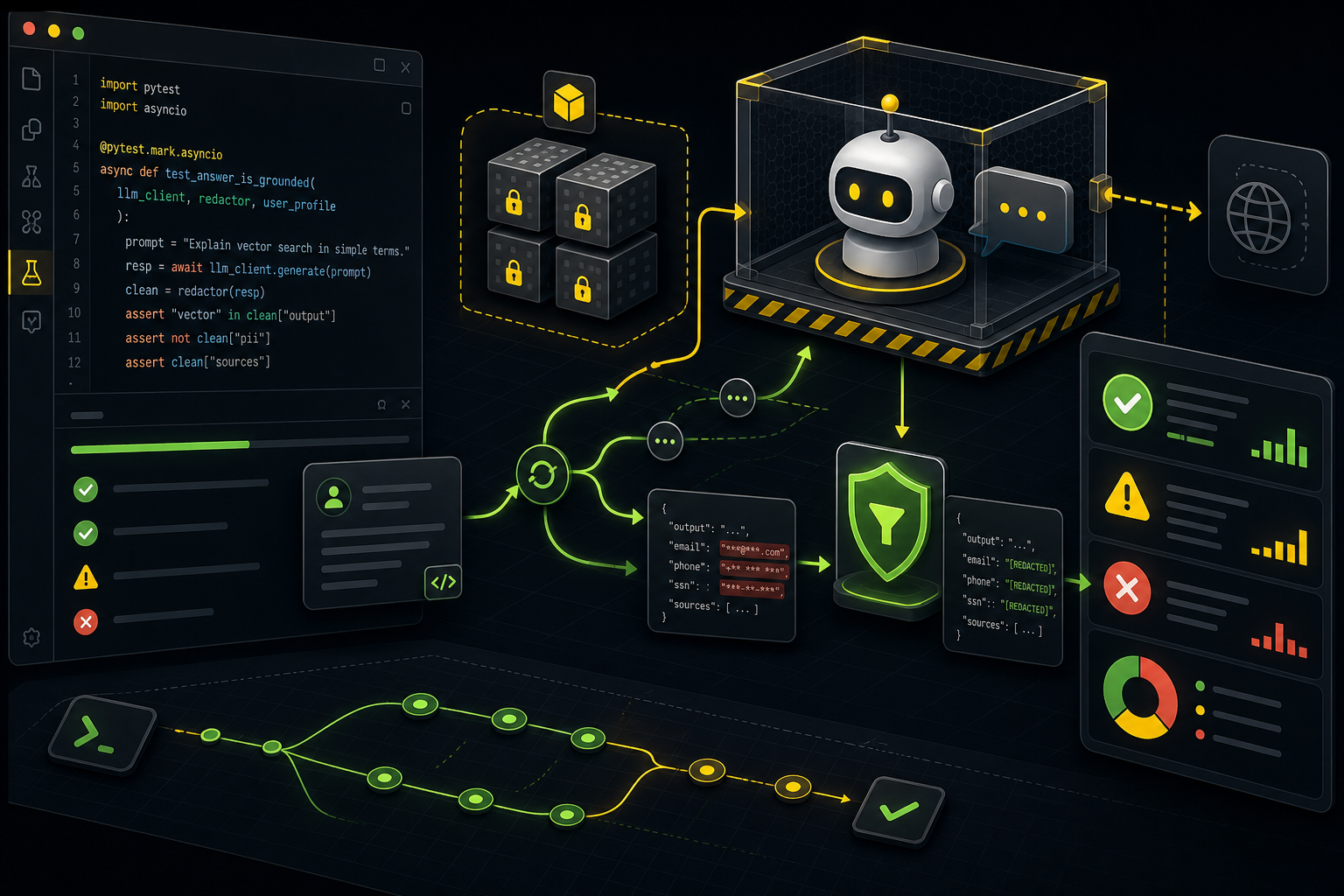
Testing LLM-powered Python code with live model calls in every test is a trap. The suite becomes slow, expensive, flaky, and unsafe to run in CI. The answer is not to avoid testing. The answer is to separate deterministic system tests from smaller live evaluation runs.
Langfuse frames the practical architecture as datasets, experiment runners, and evaluators. That maps cleanly to pytest if you treat model behavior as something to score or mock, not as a string to compare blindly.
What to unit test
Unit tests should cover deterministic code around the model.
- Prompt construction.
- Tool routing.
- JSON/schema parsing.
- Retry and timeout behavior.
- PII redaction.
- Cost and token-budget guards.
- Refusal/error handling.
- Fallback provider selection.
Mock the LLM response for these. If the parser breaks on malformed JSON, you do not need a real model to discover it.
What to evaluate
Evaluation tests check behavior across a dataset. A test case has input, expected behavior, and an evaluator. The evaluator can be code-based, semantic, or LLM-as-judge. For objective tasks, use code. If the expected answer is “Paris,” do not use a judge model when a case-insensitive contains check is enough.
def test_redaction_happens_before_llm_call(fake_client):
app = SupportBot(client=fake_client)
app.answer("My card is 4111-1111-1111-1111")
sent_prompt = fake_client.last_messages[-1]["content"]
assert "4111-1111-1111-1111" not in sent_prompt
assert "[REDACTED_CARD]" in sent_promptThresholds are normal
Traditional tests often require 100%. LLM application evaluations may use thresholds: 95% for critical behavior, 80% for less critical semantic accuracy, lower for experimental features. The threshold should reflect risk. A billing assistant and a brainstorming tool should not share the same bar.
Keep live tests explicit
Live provider tests should be opt-in, labeled, and budgeted. Run them nightly or before release, not on every file save. Store representative datasets. Track results over time. If a model upgrade improves one behavior and breaks another, you need historical comparison, not vibes.
Why pytest still matters
Pytest is excellent glue. Fixtures isolate clients. Parametrization runs datasets. Markers separate live from mocked tests. CI turns failures into gates. The LLM part is new; the engineering discipline is not.
Sources and further reading
- Langfuse, LLM Testing: A Practical Guide
- MLOps Community, Mocking LLM responses
- Dhiraj Das, pytest-mockllm project
