AI agents should not be tested like chatbots. A chatbot produces an answer. An agent changes state: it reads files, calls tools, writes code, schedules actions, edits databases, and then reports a story about what happened. Testing the story is weak. Testing the state change is the serious version.
Anthropic’s agent-evaluation guide makes this distinction clearly: an evaluation run has a task, trials, graders, a transcript or trace, and an outcome. The outcome matters because an agent can say “done” while the real environment proves otherwise. That maps directly to test automation: never trust the report if the system under test did not actually change correctly.
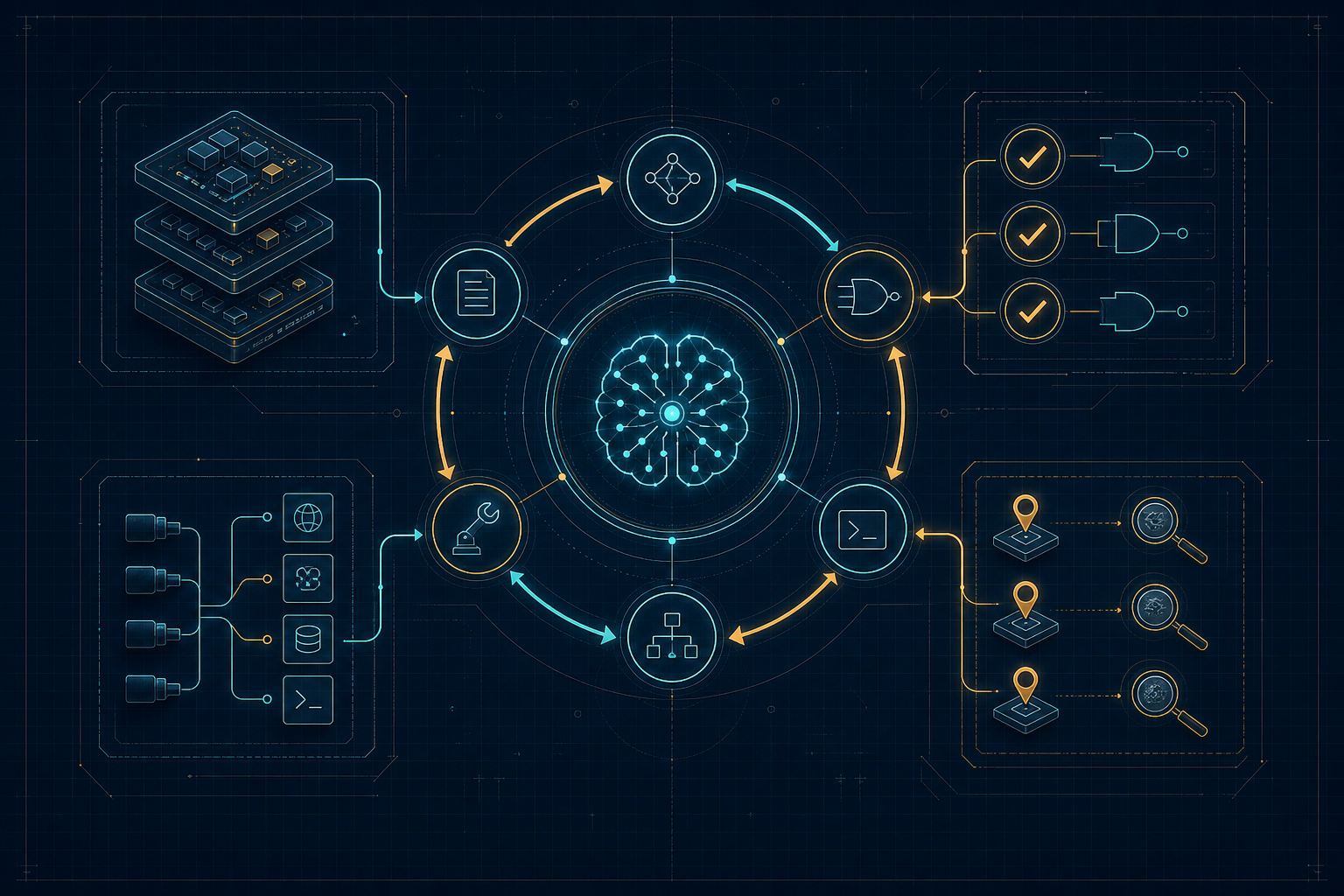
What an agent harness really is
An agent harness is everything around the model that makes action possible: context assembly, tool exposure, permission handling, execution, state capture, retries, and final reporting. When you “test an agent,” you are testing the model and the harness together. A better model inside a sloppy harness can still fail like a junior automation suite full of sleeps.
A useful harness test records four things: the initial condition, the action path, the resulting state, and the evidence behind the final claim. For coding agents, that means branch state, diffs, command output, test results, and changed files. For business-process agents, it means the external record: ticket created, meeting scheduled, customer reply drafted, invoice untouched unless approved.
The minimum test architecture
Start smaller than a platform. You need a task file, an isolated environment, a run recorder, and graders.
- Task: what the agent must do, what tools it may use, and what “done” means.
- Environment: clean repo, test database, mock service, sandbox browser, or disposable workspace.
- Trace: prompts, tool calls, command output, timing, file changes, and final message.
- Outcome grader: code, query, assertion, snapshot, or human review that checks actual state.
- Regression bank: failures that must never reappear.
user goal -> harness setup -> agent loop -> tools/environment -> trace
↓
outcome graders
↓
pass, fail, or postmortemGrade outcomes before trajectories
Trajectory checks are useful, but they can become brittle. The agent may solve a task through a different path than the one you expected. That is fine if the outcome is correct and safe. Grade the outcome first: did tests pass, did the right file change, did the database row exist, did the approval gate trigger?
Then add trajectory checks for risks that matter: did it call a forbidden tool, skip verification, exceed a cost limit, leak a secret, or use an unsafe command? This is the difference between testing for correctness and testing for operational safety.
Use three grader types
Anthropic groups graders into code-based, model-based, and human. That is the right split. Code-based graders are cheap and objective: unit tests, static analysis, regex, schema validation, database queries, tool-call checks. Model graders help when quality is subjective, but they need calibration. Human graders are slow, but they are the gold standard for ambiguous judgment.
For engineering workflows, default to code-based. Use model judges for things like “is this explanation useful?” not “did the build pass?” A model should not grade a fact that the environment can prove.
Where Agent Blackbox fits
Agent Blackbox is the local-first direction I care about here: capture the run, redact sensitive material, classify failure modes, and produce a postmortem. It is not just observability decoration. It is the evidence layer that lets failed runs become regression tests.
The path is simple: dogfood agent runs, collect traces, convert real failures into tasks, add outcome graders, and run them before trusting more autonomy. That is how agent work moves from impressive demos to repeatable engineering.
Sources and further reading
- Anthropic, Demystifying evals for AI agents
- LangChain, Agent Evaluation Readiness Checklist
- Dhiraj Das, Agentic AI Reliability
